数据库设计
个人理解说在前面:
说实话,像我们这种水平的程序员(除了菜鸟还有在公司资历不够的),估计接触不到数据库设计上的工作(除了自己写程序可以用上),所以,先了解一下就行,真想深入再去看看数据库设计的书。
至于数据库调优,这是一般是DBA干的活吧,也不是一般开发能接触到的,权限不够。
三大范式
范式指的是关系型数据库在表设计的时候遵循的规则
第一范式
字段不可再拆分,具有原子特性(最小粒度)
即某个字段不能拆分成多个信息,但这个字段究竟是否是原子性其实是主观的
比如地址:
有些可能会拆分成省、市、区、镇等,有些不做拆分
比如年级信息
有些可能学18级xx专业x班;有些又会在不同专业和年级之间拆分
所以说:某个字段是否遵循第一范式,取决于业务的需求,所以可以理解为是主观的,不是能拆就一定要拆
第二范式
在满足第一范式的基础上,还要满足数据表里的每一条数据记录,都是可唯一标识的。而且所有非主键字段,都必须完全依赖主键,不能只依赖主键的一部分,即表中字段不存在除额外的依赖关系
即通过候选键(或主键)来决定所有非主键字段的关系,
eg:有一个表里候选键和主键都为(球员编号,比赛编号)
候选键和主键可以决定其他非主键字段的信息。
(球员编号, 比赛编号) → (姓名, 年龄, 比赛时间, 比赛场地,得分)
但,其中字段也可以不完全依赖主键和候选键确定信息,这就是不完全依赖(只依赖一部分)
(球员编号) → (姓名,年龄)
(比赛编号) → (比赛时间, 比赛场地)
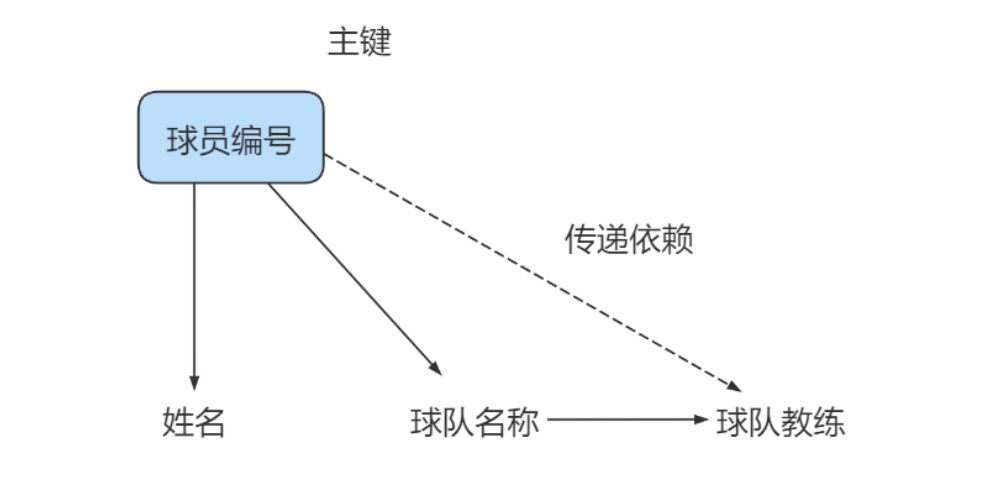
第三范式
非主键字段,不能存在间接依赖。要求数据表中的所有非主键字段不能依赖于其他非主键字段。(即,不能存在非主属性A依赖于非主属性B,非主属性B依赖于主键C的情况,即存在"A–>B–>C"的决定关系)通俗地讲,该规则的意思是所有非主键属性之间不能有依赖关系,必须相互独立。
2NF和3NF通常以这句话概括:“每个非键属性依赖于键,依赖于整个键,并且除了键别无他物”。
其实暴力一点讲就是,一条记录的非主键字段值只能通过主键确定,不能通过非主键字段就查得出来
eg:球员表: 球员编号、姓名、球队名称和球队主教练。
显然球队主教练可以通过球队名称查出来。
反范式化
根据业务,适当的冗余存储字段,减少多表查询的压力
规范化 vs 性能
- 为满足某种商业目标 , 数据库性能比规范化数据库更重要
- 在数据规范化的同时 , 要综合考虑数据库的性能
- 通过在给定的表中添加额外的字段,以大量减少需要从中搜索信息所需的时间
- 通过在给定的表中插入计算列,以方便查询
范式是一种规则,规则的制定就会有一定的约束性,所以有时候墨守成规反而没那么好,因而在为了性能提升上,范式也是可以不遵守滴。
数据库对象编写建议
1、关于库
略
2、关于表、列
略
3、关于索引
- 【强制】InnoDB表必须主键为id int/bigint auto_increment,且主键值 禁止被更新 。
- 【强制】InnoDB和MyISAM存储引擎表,索引类型必须为 BTREE 。
- 【建议】主键的名称以 pk_ 开头,唯一键以 uni_ 或 uk_ 开头,普通索引以 idx_ 开头,一律使用小写格式,以字段的名称或缩写作为后缀。
- 【建议】多单词组成的columnname,取前几个单词首字母,加末单词组成column_name。如:sample 表 member_id 上的索引:idx_sample_mid。
- 【建议】单个表上的索引个数 不能超过6个 。
- 【建议】在建立索引时,多考虑建立 联合索引 ,并把区分度最高的字段放在最前面。
- 【建议】在多表 JOIN 的SQL里,保证被驱动表的连接列上有索引,这样JOIN 执行效率最高。
- 【建议】建表或加索引时,保证表里互相不存在 冗余索引 。 比如:如果表里已经存在key(a,b),则key(a)为冗余索引,需要删除。
4、SQL编写
- 【强制】程序端SELECT语句必须指定具体字段名称,禁止写成 *。
- 【建议】程序端insert语句指定具体字段名称,不要写成INSERT INTO t1 VALUES(…)。
- 【建议】除静态表或小表(100行以内),DML语句必须有WHERE条件,且使用索引查找。
- 【建议】INSERT INTO…VALUES(XX),(XX),(XX)… 这里XX的值不要超过5000个。 值过多虽然上线很快,但会引起主从同步延迟。
- 【建议】SELECT语句不要使用UNION,推荐使用UNION ALL,并且UNION子句个数限制在5个以内。
- 【建议】线上环境,多表 JOIN 不要超过5个表。
- 【建议】减少使用ORDER BY,和业务沟通能不排序就不排序,或将排序放到程序端去做。ORDER BY、GROUP BY、DISTINCT 这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
- 【建议】包含了ORDER BY、GROUP BY、DISTINCT 这些查询的语句,WHERE 条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
- 【建议】对单表的多次alter操作必须合并为一次对于超过100W行的大表进行alter table,必须经过DBA审核,并在业务低峰期执行,多个alter需整合在一起。 因为alter table会产生 表锁 ,期间阻塞对于该表的所有写入,对于业务可能会产生极大影响。
- 【建议】批量操作数据时,需要控制事务处理间隔时间,进行必要的sleep。
- 【建议】事务里包含SQL不超过5个。因为过长的事务会导致锁数据较久,MySQL内部缓存、连接消耗过多等问题。
- 【建议】事务里更新语句尽量基于主键或UNIQUE KEY,如UPDATE… WHERE id=XX;否则会产生间隙锁,内部扩大锁定范围,导致系统性能下降,产生死锁。
数据库调优策略
1、调优的目标
尽可能节省系统资源 ,以便系统可以提供更大负荷的服务。(吞吐量更大)
合理的结构设计和参数调整,以提高用户操作响应的速度 。(响应速度更快)
减少系统的瓶颈,提高MySQL数据库整体的性能。
2、调优的维度和步骤
1、选择适合的 DBMS
2、优化表设计
根据实际需求你改变字段的数据类型,来减少占用的空间,从而减少IO次数,提升性能
3、优化逻辑查询
改写sql语句
4、优化物理查询
物理查询优化是在确定了逻辑查询优化之后,采用物理优化技术(比如索引等),
通过计算代价模型对各种可能的访问路径进行估算,从而找到执行方式中代价最小的作为执行计划。
5、使用 Redis 或 Memcached 作为缓存
当用户量增大的时候,如果频繁地进行数据查询,会消耗数据库的很多资源。
如果我们将常用的数据直接放到内存中,就会大幅提升查询的效率。
6、库级优化
1、读写分离
有一主一从;多主多从等方案。多主多从比较常见,实际生产应该不会单主机,必须要有冗余作为后备。
2、数据分片
分片和分区
mysql的分表是真正的分表,一张表分成很多表后,每一个小表都是完整的一张表,(MyISAM中都对应三个文件,一个.MYD数据文件,.MYI索引文件,.frm表结构,InnoDB中则是一个文件)。
分区不一样,一张大表进行分区后,他还是一张表,不会变成二张表,但是他存放数据的区块变多了。
分区(Partition)
优点:业务无感,多个物理存储,逻辑上还是一张表
局限:局限于单库,不能跨主机
适用:数据量不超过单主机物理承载
分片(sharding)
优点:无限扩展,可以跨库、跨主机
局限:扩展时需要调整业务配置
适用:
垂直分片:不同的表分散到不同的数据库或主机,适用于低耦合系统;
水平分片:同一张表的数据分散到不同的数据库或主机,适用于复杂系统。
分库分表存在的问题。
1、事务问题。
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
2、跨库跨表的join问题。
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
3、额外的数据管理负担和数据运算压力。
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
优化MySQL服务器
1、优化服务器硬件
服务器的硬件性能直接决定着MySQL数据库的性能。硬件的性能瓶颈直接决定MySQL数据库的运行速度和效率。针对性能瓶颈提高硬件配置,可以提高MySQL数据库查询、更新的速度。
1、配置较大的内存
2、配置高速磁盘系统
3、合理分布磁盘I/O
4、配置多处理器
2、优化MySQL的参数
这个参数好多,不记了。
有像innodb_buffer_pool_size缓冲池的;
thread_cache_size : 线程池缓存线程数量的大小等等
分析表、检查表与优化表
这是开发干的?不是吧?不记了,哈哈哈哈