服务器处理客户端的请求
客户端向服务器发送请求的过程做了什么处理,才能产生最后的处理结果呢?
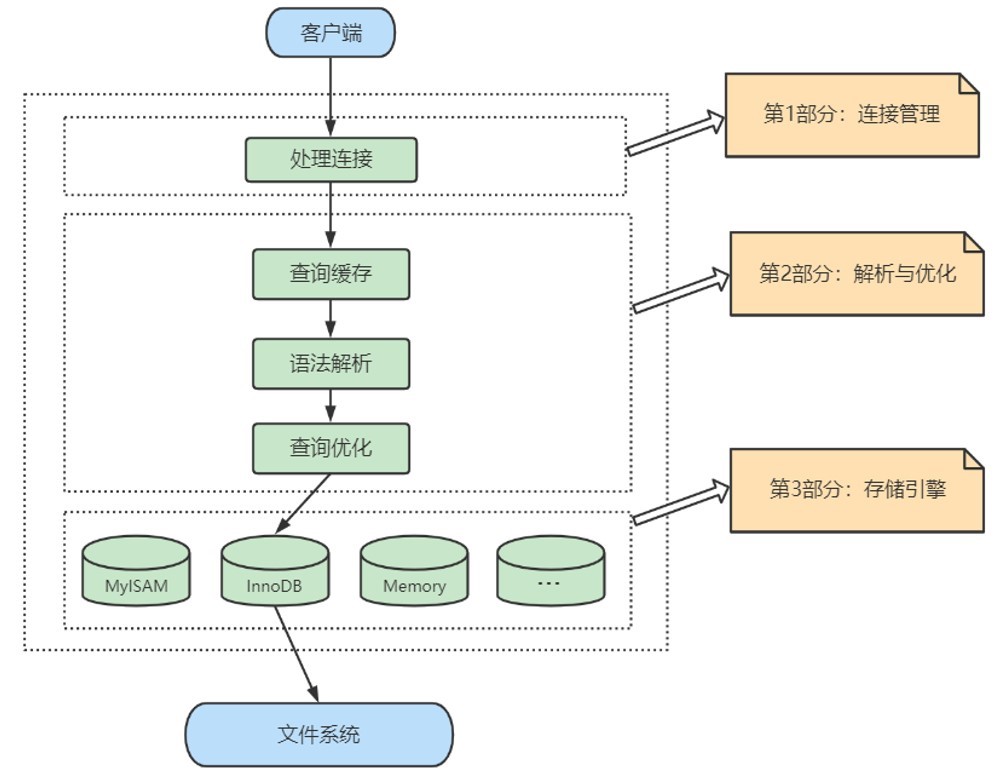
将以上步骤简化:
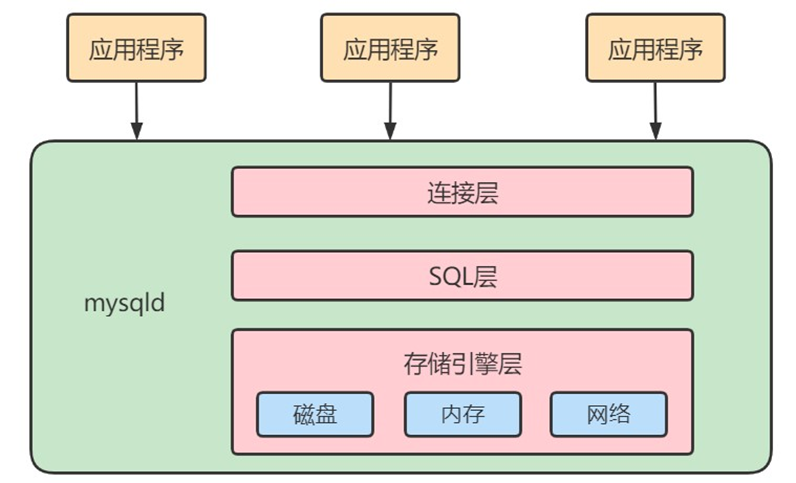
简化为三层结构:
1.连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端;
经过三次握手建立连接成功后, MySQL 服务器对 TCP 传输过来的账号密码做身份认证、权限获取。
2.SQL 层(服务层):对 SQL 语句进行查询处理;与数据库文件的存储方式无关;
1、SQL Interface: SQL接口,接收用户的SQL命令,并且返回用户需要查询的结果。
2、Parser: 解析器:在解析器中对 SQL 语句进行语法分析、语义分析。
将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于
这个结构的。在SQL命令传递到解析器的时候会被解析器验证和解析,并为其创建 语法树 ,
并根据数据字典丰富查询语法树,会 验证该客户端是否具有执行该查询的权限 。
3、Optimizer: 查询优化器:SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL
语句的执行路径,生成一个执行计划 。
3.存储引擎层:与数据库文件打交道,负责数据的存储和读取。
真正的负责了MySQL中数据的存储和提取,对物理服务器级别
维护的底层数据执行操作,服务器通过API与存储引擎进行通信。
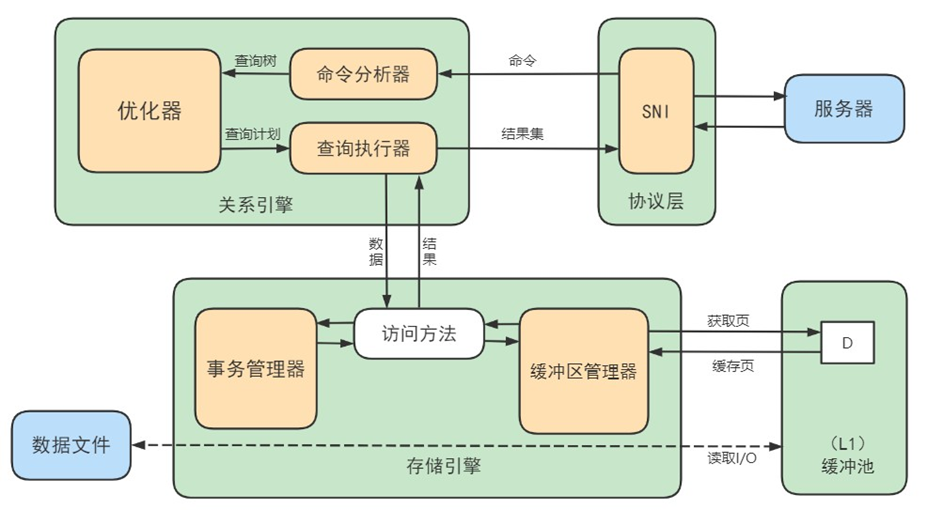
SQL的执行流程
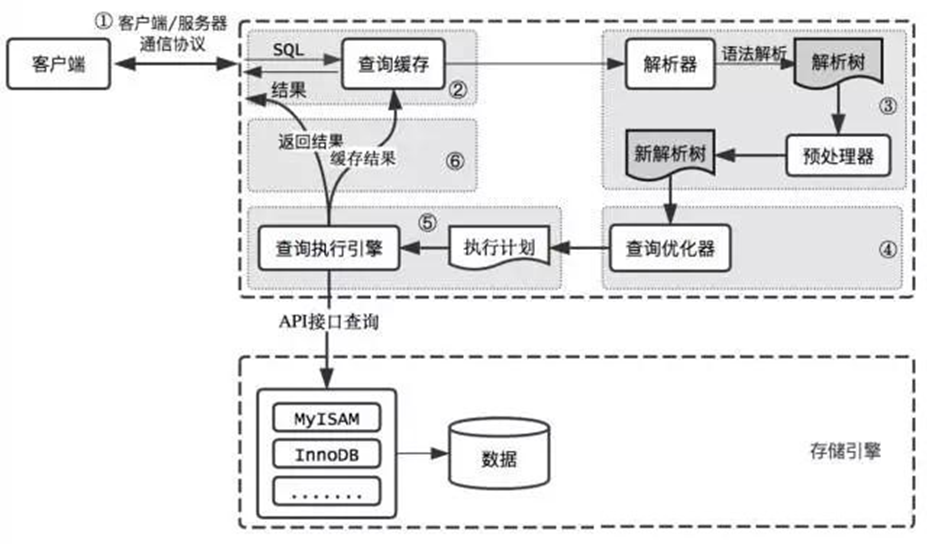
- 查询缓存,此功能在MySQL8.0后被废弃,原因是命中的条件太苛刻。
- 解析器:在解析器中对 SQL 语句进行语法分析、语义分析。
- 优化器:在优化器中会确定 SQL 语句的执行路径,比如是根据 全表检索 ,还是根据 索引检索 等。
- 执行器:在执行之前需要判断该用户是否 具备权限 。如果没有,就会返回权限错误。如果具备权限,就执行 SQL查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
总结:SQL 语句在 MySQL 中的流程是: SQL语句→查询缓存→解析器→优化器→执行器 。

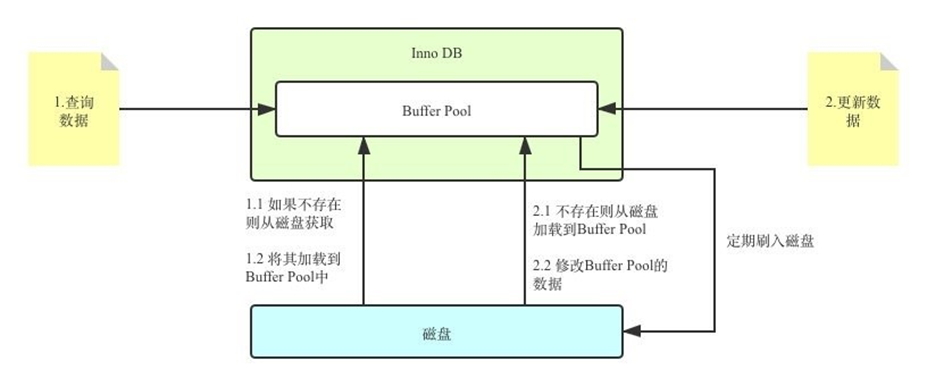
数据库缓冲池(buffer pool)
首先,我们访问服务器的一切操作本质上都是增删改查。
如果直接和磁盘交互,磁盘 I/O 需要消耗的时间很多,而在内存中进行操作,效率则会高很多,
为了能让数据表或者索引中的数据随时被我们所用,DBMS 会申请 占用内存来作为
数据缓冲池 ,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的 Buffer Pool 之后才可以访
问。减少与磁盘直接进行 I/O 的时间 。
注:缓冲池和查询缓存不是一个东西,查询缓存只是结果的缓存,缓冲池则包括了以下内容
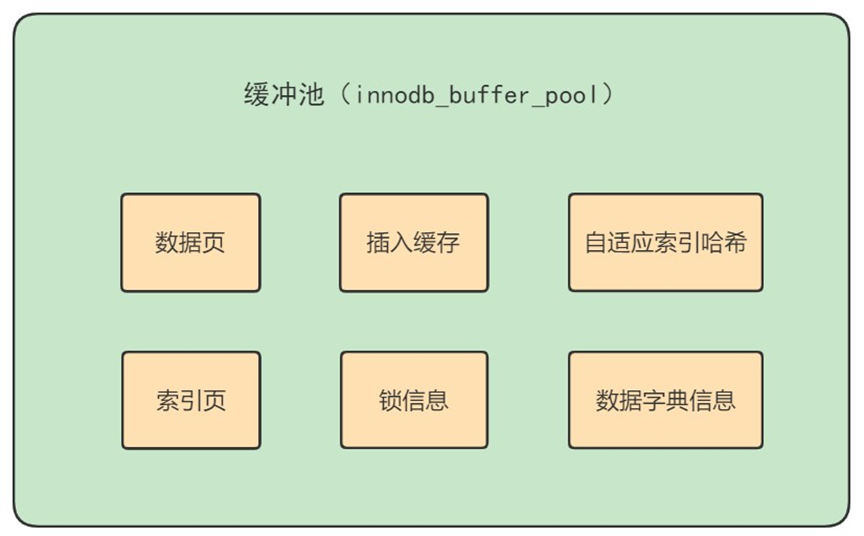
缓冲池如何读取数据?
缓冲池管理器会尽量将经常使用的数据保存起来,在数据库进行页面读操作的时候,首先会判断该页面
是否在缓冲池中,如果存在就直接读取,如果不存在,就会通过内存或磁盘将页面存放到缓冲池中再进
行读取。
引申问题一:为什么要缓存?CPU;内存;磁盘和缓存的关系
粗浅的理解:
可以将CPU比作火箭;内存比作小车;磁盘比作步行。
CPU处理数据的速度极快,磁盘的写入和写出数据的速度极慢,内存处于两者中间
CPU不可能只处理某一个请求。且CPU速度比内存快了十几倍(可能更高也可能更低),
如果它停下来等内存,就少执行了至少几十条指令
——倘若等硬盘,几亿条指令的执行机会就白白放弃了。
因此,在高速设备和低速设备的交界面处,我们会设置一种叫“缓存”的东西
通过缓存,我们可以给较慢的内存(很慢的硬盘)发一条指令——把xx数据准备好,等下我来取!然后执行别的指令去。
因而硬盘会先把数据放进缓存(硬盘线路板上面的缓存),然后这些数据进一步放进内存缓存起来、
最终还得在CPU的一二三级缓存里缓存。
总结来说就是为了提高执行效率。
但为什么加了缓存就能提高效率呢?怎么知道要哪些数据?
这里就要说到预读机制了
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),
如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
如果要读取的数据不在页中呢?那么这就出现预读失效的问题
预读为什么有效?
数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,
这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
以上来源于:
cpu —>内存—>硬盘这种方式是不是更慢? - invalid s的回答 - 知乎
https://www.zhihu.com/question/423243212/answer/1504942172
https://blog.51cto.com/jyjstack/2548713?articleABtest=0
更详细可以跳转去看看,很好的回答和博客
引申问题二:缓存的数据更新问题
缓存池的数据更新操作对我们来说完全就是黑盒操作,如果在更新到一半突然发生错误了,
想要回滚到更新之前的版本,该怎么办?连数据持久化的保证、事务回滚都做不到还谈什么崩溃恢复?
解决就是依靠Redo Log & Undo Log。此处在日志里再描述