Redis并发访问
并发,简单理解就是多个线程操作同一份数据。
并发应对
1、加锁
缺点:加锁操作多,会降低系统的并发访问性能;Redis 客户端要加锁时,需要用到分布式锁(只有一个缓存另说),
而分布式锁实现复杂,需要用额外的存储系统来提供加解锁操作
2、原子操作
指执行过程保持原子性的操作
修改数据时,基本流程为:读取 - 修改 - 写回(Read-Modify-Write,简称为 RMW 操作)。(之所以会有并发问题是因为有别的操作在一连续操作中插队读取或修改数据,最后写回,导致出现数据与预期不一致的问题)
Redis原子操作方法
1、把多个操作在 Redis 中实现成一个操作,也就是单命令操作;
例如Redis 提供了 INCR/DECR 命令,把读数据、数据增减、写回数据三个操作转变为一个原子操作。
INCR/DECR 命令可以对数据进行增值 / 减值操作,而且它们本身就是单个命令操作,
Redis 在执行它们时,本身就具有互斥性。
2、把多个操作写到一个 Lua 脚本中,以原子性方式执行单个 Lua 脚本。
实际中要执行的操作可能不是简单地增减数据,而是有更加复杂的判断逻辑或者是其他操作。
Redis 的单命令操作已经无法保证多个操作的互斥执行了。
为此可以将要执行的操作编写到Lua脚本中,使用 Redis 的 EVAL 命令来执行脚本
Redis 会把整个 Lua 脚本作为一个整体执行,在执行的过程中不会被其他命令打断,从而
保证了 Lua 脚本中操作的原子性。
Redis分布式锁
分布式锁
当多个进程不在同一个系统中时,用分布式锁控制多个进程对资源的访问。
在分布式系统中,当有多个客户端需要获取锁时,我们需要分布式锁。此时,
锁是保存在一个共享存储系统中的,可以被多个客户端共享访问和获取。
基于单个 Redis 节点实现分布式锁
单个Redis节点实现的分布式锁我感觉都不能算是分布式锁。因为只是数据变量放到缓存中而已。这和自己写一个多线程的demo时定义一个公共变量没啥区别。所以单个Redis节点的加锁和普通的加锁流程一样。
加锁包含了三个操作(读取锁变量、判断锁变量值以及把锁变量值设置为 1),而这
三个操作在执行时需要保证原子性。
保证原子性的方法又有单命令操作和lua脚本
1、单命令操作
SETNX key val
当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
执行完业务逻辑后,删除锁变量。
但会有两个问题:
1、如果在加锁之后阻塞了或者发生异常,那么删除操作就无法执行,其他客户端就不能进行加锁操作
2、某客户端加锁后,可能会被其他客户端执行删除操作删除掉锁。
对于第一个问题,解决办法是使用expire设置过期时间
第二个问题则是,客户端在加锁时加入标识,在删除是进行标识判断,防止误删。
但在上述中,又是setnx,又是expire的,最终还是有多条指令。
为了能达到和 SETNX 命令一样的效果,Redis 给 SET 命令提供了类似的选项 NX,用来实现“不存在即设置”。
SET key value [EX seconds | PX milliseconds] [NX]
且加入EX 或 PX 选项,用来设置键值对的过期时间。
2、lua脚本
在删除锁实现释放变量时使用lua脚本,因为,释放锁操作的逻辑也包含了读取锁变量、判断值、删除锁变量
的多个操作,而 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
--
**对上面这段话我持保留意见,因为删除操作只要知道key就行,不是必要进行判断。**
在实际分布式锁中,无论是否加锁成功都建议进行一次删锁操作,因为可能存在缓存中加锁成功但因为网络等
问题,没能回馈给客户端,让客户端以为没能加锁成功,最后锁一直存在的问题
基于多个 Redis 节点实现高可靠的分布式锁
多个Redis节点实现的分布式锁,其实是为了防止只有一个节点的实现在出现宕机等问题后锁不能工作的问题。
因此需要按照一定的步骤和规则进行加解锁操作,这一定的步骤和规则就是分布式算法。
分布式锁算法 Redlock
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户
端能够和半数以上的实例成功地完成加锁操作,那么就认为,客户端成功地获得分布式锁了,否则加锁失败
Redlock 算法的执行步骤
1、客户端获取当前时间
2、客户端按顺序依次向 N 个 Redis 实例执行加锁操作
3、一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
获取锁的总耗时没有超过锁的有效时间且从半数以上的Redis实例上获取了锁,则加锁成功,
加锁成功后还要重新计算锁的有效期,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。
如果锁的有效时间已经来不及完成共享数据的操作了,可以释放锁,以免出现还没完成数据操作,
锁就过期了的情况。
分布式锁相关(RedLock算法)可以看这篇博客:http://zhangtielei.com/posts/blog-redlock-reasoning.html
Redis事务
事务属性
原子性(Atomicity)
一致性(Consistency)
隔离性(Isolation)
持久性(Durability)
即 ACID 属性
Redis如何实现事务
1、使用MULTI开启事务
2、发送具体的要执行的操作命令,这些命令虽然被客户端发送到了服务器端,但 Redis 实例只是把这些命令暂存到一个命令队列中,并不会立即执行。
3、 EXEC 提交事务
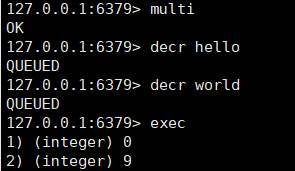
Redis事务机制能保证哪些属性
原子性
1、如果在执行 EXEC 命令前,客户端发送的操作命令本身就有错误(比如语法错误,使用了不存在的命令),在命令入队时就被 Redis 实例判断出来了。
在错误命令入队时就会被记录下来,但也能继续提交事务,只是提交事务后,
Redis 就会拒绝执行所有提交的命令操作,返回事务失败的结果。保证原子性
2、如果是事务操作入队时,命令和操作的数据类型不匹配,但 Redis 实例没有检查出错误。那么虽然 Redis 会对错误命令报错,但还是会把正确的命令执行完。在这种情况下,事务的原子性就无法得到保证了。
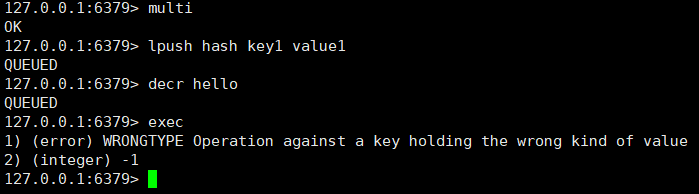
例如对数据类型为hash的数据使用操作list数据类型的lpush命令,Redis没检查出来,最后事务提交的时候,
会报错,但对hello的减一操作还是继续执行,没能保证原子性
3、在执行事务的 EXEC 命令时,Redis 实例发生了故障,导致事务执行失败。
如果有AOF日志记录,可以根据日志对最后的事务操作进行选择(不全的去掉或者完整留下),保证原子性,
如果没有日志记录(RDB不一定能记下来),那么也就谈不上原子性,毕竟原来的实例数据都不能恢复了
注:
和MySQL不同的是
Redis 中并没有提供回滚机制。虽然 Redis 提供了 DISCARD 命令,但是,这个命
令只能用来主动放弃事务执行,把暂存的命令队列清空,起不到回滚的效果。
且为什么第2中情况Redis会允许,还不能保证原子性,因为对设计者来说,这种现象属于是Redis的使用者
的问题,是可以避免的,不属于Redis的问题
一致性
1、命令入队时出错
没有执行,那么不会有数据变化,一致
2、命令实际执行时出错
错误命令不执行,正确的命令执行,一致
3、在EXEC 命令执行时实例发生故障
没有日志,不存在一致性问题
有日志,RDB日志不会在事务执行时执行,所以不会保存,恢复后一致
AOF日志如果记录有全部操作,一致,记录部分操作,可以删掉这些部分操作,最终也一致
一致性可以得到保障
隔离性
和并发操作一起理解就行,因为没有加锁
1、并发操作在 EXEC 命令前执行,此时,隔离性的保证要使用 WATCH 机制来实现,否则隔离性无法保证;
WATCH 机制的作用是,在事务执行前,监控一个或多个键的值变化情况,当事务调用
EXEC 命令执行时,WATCH 机制会先检查监控的键是否被其它客户端修改了。如果修改
了,就放弃事务执行,避免事务的隔离性被破坏。
2、并发操作在 EXEC 命令后执行,此时,隔离性可以保证。
持久性
在RDB和AOF中有说到,无论是哪种日志模式,某些时刻都会有一定程度的数据丢失问题,所以Redis的持久性不能保障
主从集群中的脑裂
所谓的脑裂,就是指在主从集群中,同时有两个主节点,它们都能接收写请求。而脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客户端会往不同的主节点上写入数据。而且,严重的话,脑裂会进一步导致数据丢失。
脑裂的原因
主库是由于某些原因无法处理请求,也没有响应哨兵的心跳,才被哨兵错误地判断为客观下线的。即出现假故障。
脑裂造成的数据丢失
主库出现假故障被判断下线之后,原主库又重新开始处理请求了,而此时,哨兵还没有完成主从切换,客户端仍然可以和原主库通信,客户端发送的写操作就会在原主库上写入数据了。
完成主从切换之后,哨兵会让原主库和新主库做全量同步操作,这样,原本接收的请求虽然写进了原主库,也会被清楚掉,造成数据丢失。
脑裂的应对
Redis 已提供了两个配置项来限制主库的请求处理,分别是 min-slaves-to-write 和 min-slaves-max-lag。
min-slaves-to-write:这个配置项设置了主库能进行数据同步的最少从库数量;
min-slaves-max-lag:这个配置项设置了主从库间进行数据复制时,从库给主库发送
ACK 消息的最大延迟(以秒为单位)。
即使原主库是假故障,它在假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然也就无法和从库进行 ACK 确认了。这样一来,min-slaves-to-write 和 min-slaves-max-lag 的组合要求就无法得到满足,原主库就会被限制接收客户端请求,客户端也就不能在原主库中写入新数据了。