前言
主从复制的问题涉及到前面说到的binlog日志问题,而且对于主从复制的实操我是不熟练的,这里只能是浅显的记录一下。
主从复制,要先有主才会有从,为什么要有主从,主要是为了提升数据库并发能力。主库负责写,从库负责读,在主库写入数据后,要更新到从库,这就是主从复制,这期间会涉及到很多问题。
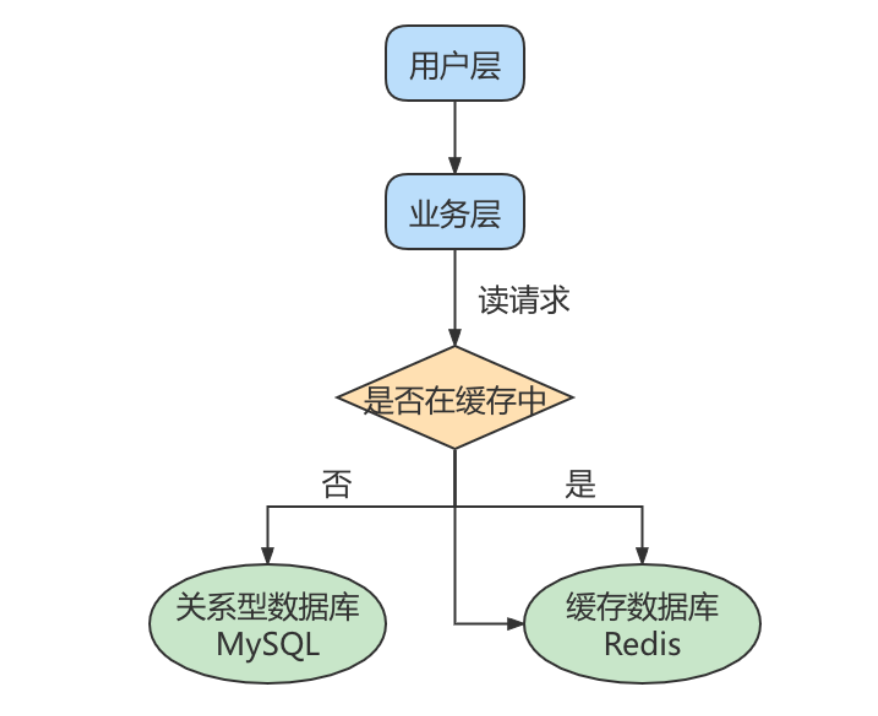
一般应用对数据库而言都是“ 读多写少 ”,也就说对数据库读取数据的压力比较大,有一个思路就是采用数据库集群的方案,做 主从架构 、进行 读写分离 ,这样同样可以提升数据库的并发处理能力。但并不是所有的应用都需要对数据库进行主从架构的设置,毕竟设置架构本身是有成本的。
其实如果我们的目的在于提升数据库高并发访问的效率,那么首先考虑的是如何 优化SQL和索引 ,这种方式简单有效;其次才是采用 缓存的策略 ,比如使用 Redis将热点数据保存在内存数据库中,提升读取的效率;最后才是对数据库采用 主从架构 ,进行读写分离。
主从复制的作用
读写分离。
主写从读
数据备份。
多个库就是多份数据
具有高可用性。
高可用这个概念百度一下
主从复制的原理
主从同步的原理就是基于 binlog 进行数据同步的。在主从复制过程中,会基于 3 个线程 来操作,一个主库线程,两个从库线程。
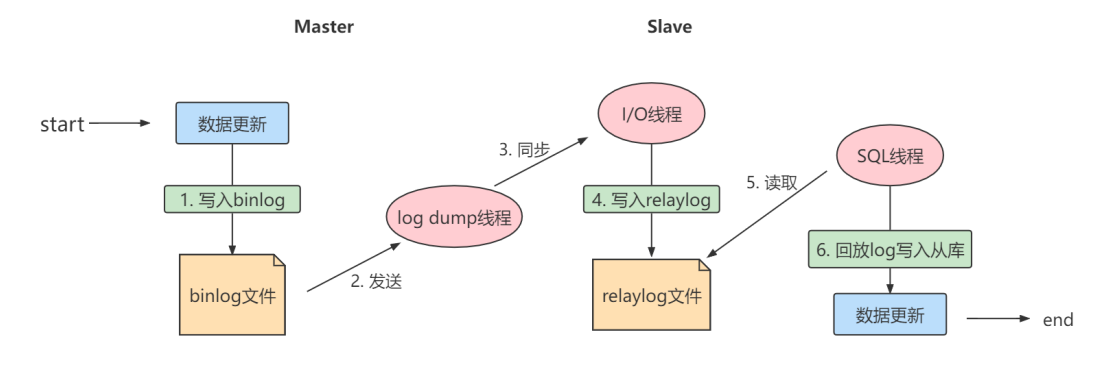
二进制日志转储线程 (Binlog dump thread)是一个主库线程。当从库线程连接的时候, 主库可以将二进
制日志发送给从库,当主库读取事件(Event)的时候,会在 Binlog 上 加锁 ,读取完成之后,再将锁释
放掉。
从库 I/O 线程 会连接到主库,向主库发送请求更新 Binlog。这时从库的 I/O 线程就可以读取到主库的
二进制日志转储线程发送的 Binlog 更新部分,并且拷贝到本地的中继日志 (Relay log)。
从库 SQL 线程 会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
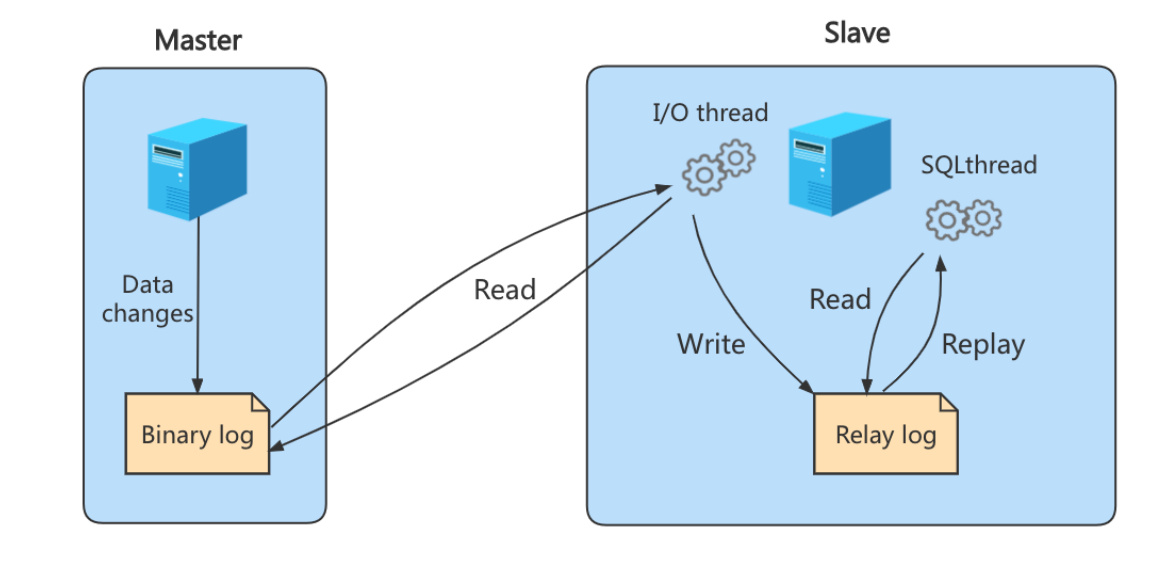
复制三步骤
步骤1: Master 将写操作记录到二进制日志( binlog )。
步骤2: Slave 将 Master 的binary log events拷贝到它的中继日志( relay log );
步骤3: Slave 重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化
的,而且重启后从 接入点 开始复制。
复制的问题
复制的最大问题: 延时
同步数据一致性问题
主从同步的要求:
读库和写库的数据一致(最终一致);
写数据必须写到写库;
读数据必须到读库(但读库不一定就是固定一台机器,这个概念要分清,主从是能转换的);
主从延迟问题
进行主从同步的内容是二进制日志,它是一个文件,在进行 网络传输 的过程中就一定会 存在主从延迟(比如 500ms),这样就可能造成用户在从库上读取的数据不是最新的数据,也就是主从同步中的 数据不一致性 问题。
主从延迟问题原因
主备延迟最直接的表现是,从库消费中继日志(relay log)的速度,比主库生产binlog的速度要慢。造成原因:
1、从库的机器性能比主库要差
2、从库的压力大
3、大事务的执行
如何减少主从延迟
- 降低多线程大事务并发的概率,优化业务逻辑
- 优化SQL,避免慢SQL, 减少批量操作 ,建议写脚本以update-sleep这样的形式完成。
- 提高从库机器的配置 ,减少主库写binlog和从库读binlog的效率差。
- 尽量采用 短的链路 ,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输
的网络延时。 - 实时性要求的业务读强制走主库,从库只做灾备,备份。
如何解决一致性问题
读写分离情况下,解决主从同步中数据不一致的问题, 就是解决主从之间 数据复制方式 的问题,如果按照数据一致性 从弱到强 来进行划分,有以下 3 种复制方式。
1、异步复制
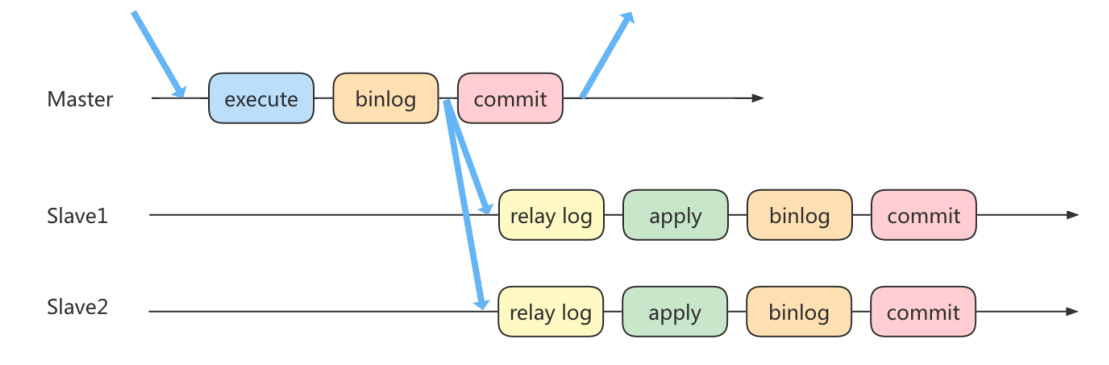
可能的问题:要是从库同步主库的时候会有时间差,这就是延迟;要是在同步的时候主库挂了,那么同步的数据没完成,从库要是升级为主库,那么这些数据就没了;
2、半同步复制
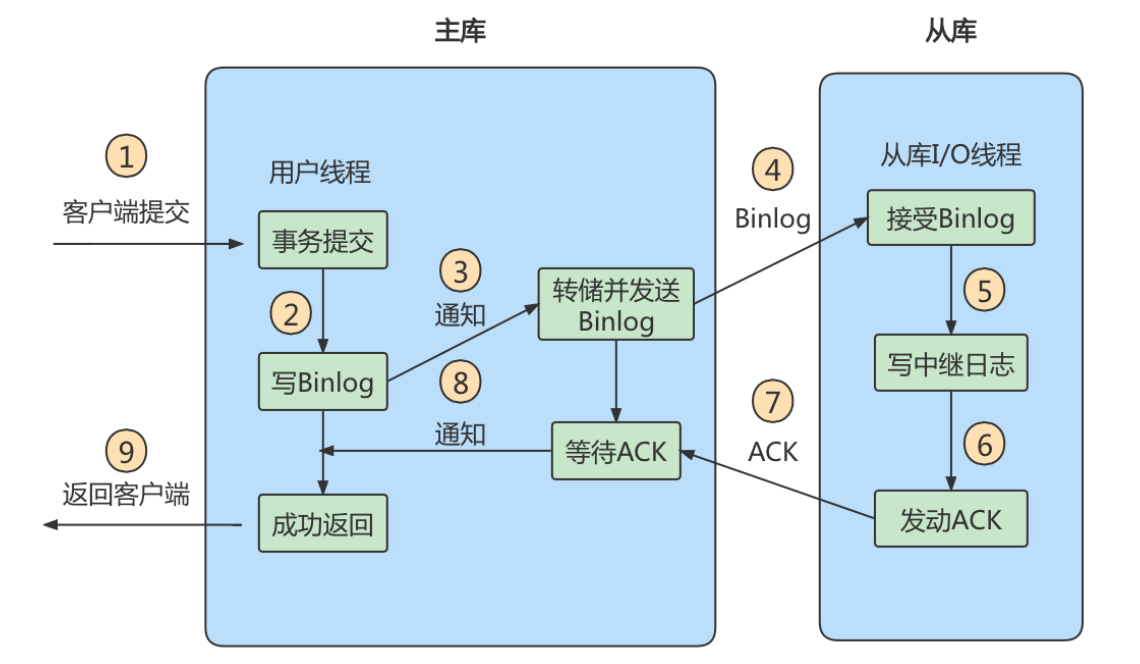
半同步虽然比异步好一点,但要等待返回结果,这会增加耗时
异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制是通过判断从库响应的个数来决定是否返回给客户端,虽然数据一致性相比于异步复制有提升,但仍然无法满足对数据一致性要求高的场景
3、组复制
将多个节点共同组成一个复制组,在 执行读写(RW)事务 的时候,需要通过一致性协议层(Consensus 层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应 Node 节点)的同意,大多数指的是同意的节点数量需要大于 (N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对 只读(RO)事务 则不需要经过组内同意,直接 COMMIT 即可。在一个复制组内有多个节点组成,它们各自维护了自己的数据副本,并且在一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性。
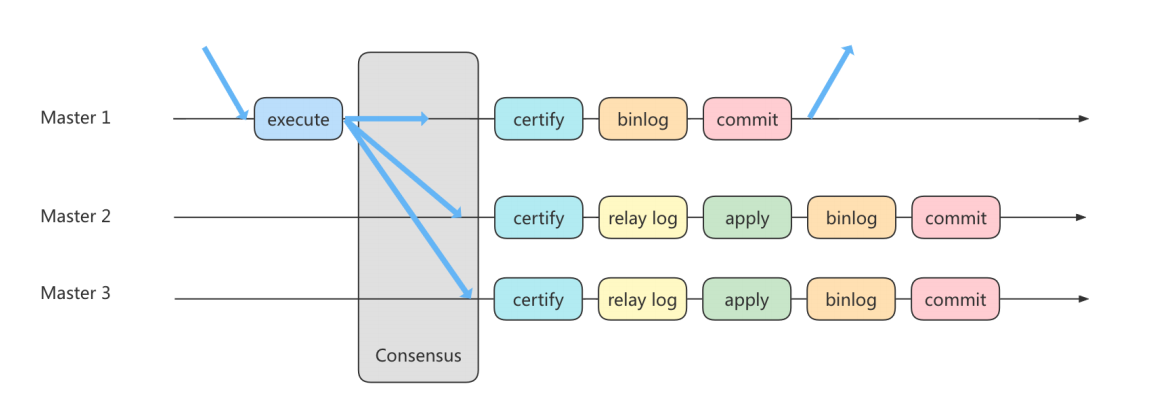
不熟,看不懂,留着
主从复制有不同的复制策略,对于不同的场景的适应性也不同,对于数据的实时性要求很高,要求强一致性,可以采用同步复制策略,但是这样就会性能就会大打折扣。
若是主从复制采用异步复制,要求数据最终一致性,性能方面也会好很多。只能说,对于数据延迟的解决方案没有最好的方案,就看你的业务场景中哪种方案使比较适合的。